
gemini3怎么搭建智能体
下面这个图就是我在Gemini上搭建过的智能体,我只需要点开某一个智能体,它就能帮我快速完成相应的任务。
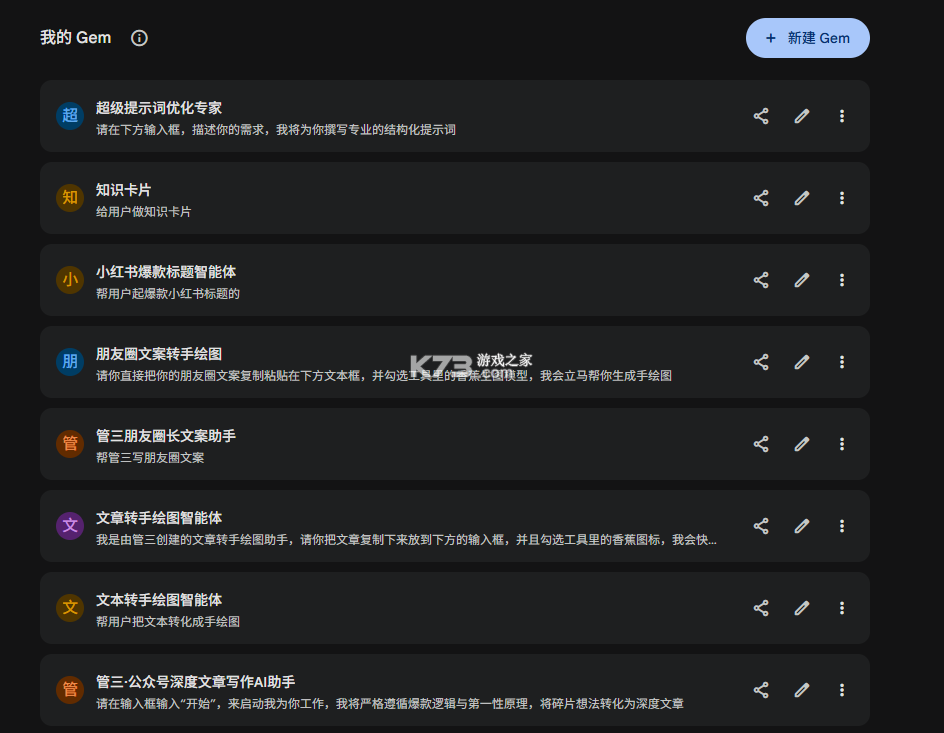
那么在Gemini上面如何搭建智能体呢?
这就需要用到Gemini里的一个功能:Gem
它在Gemini官网左上方,点击Gem就可以去创建智能体。
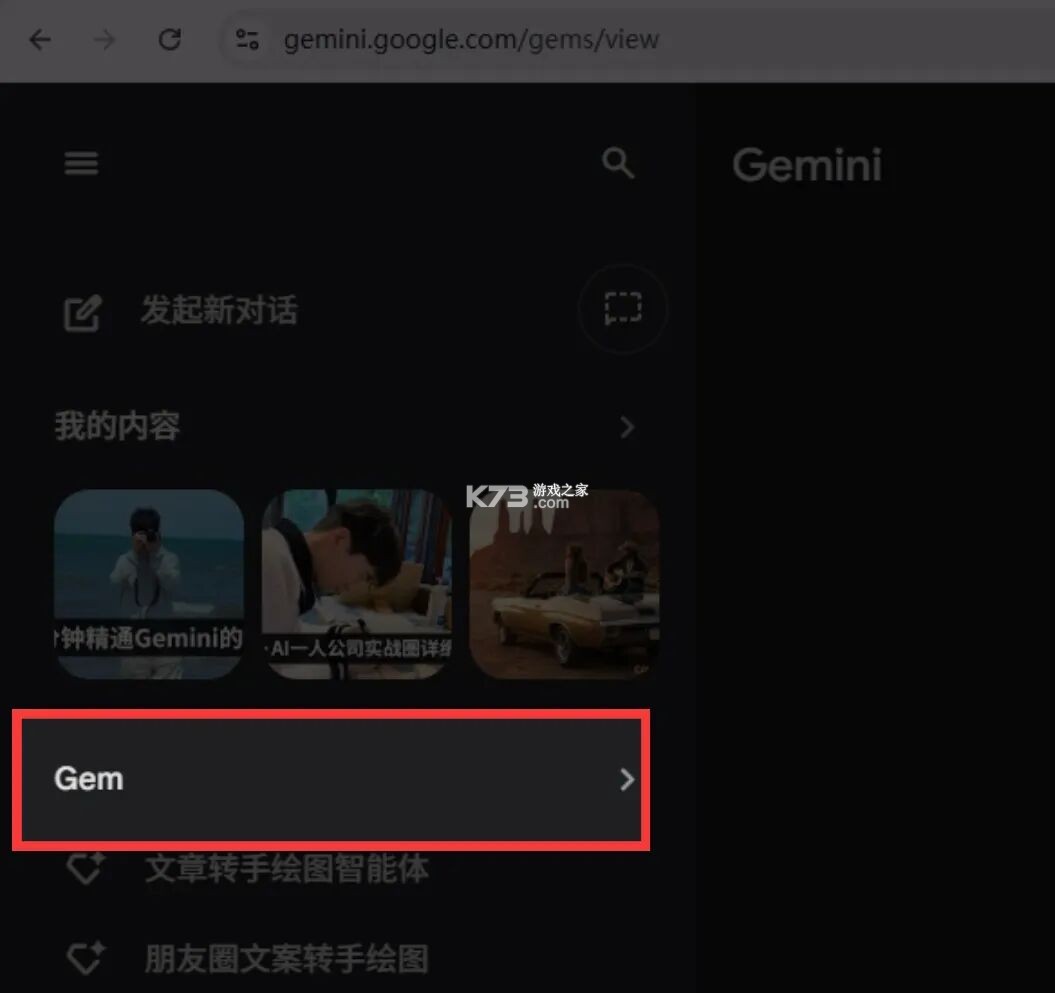
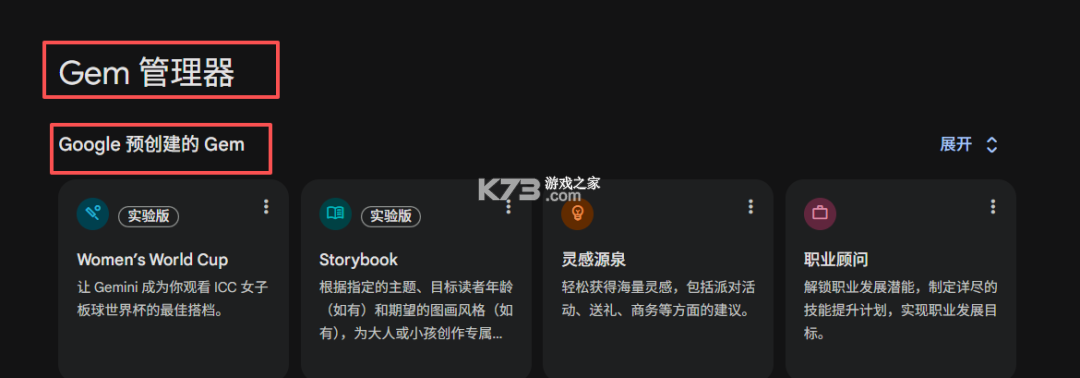
点进去之后,我们能看到有一个【Gem管理器】,它下面有谷歌为我们预先创建好的4个智能体,我们是可以直接用的。
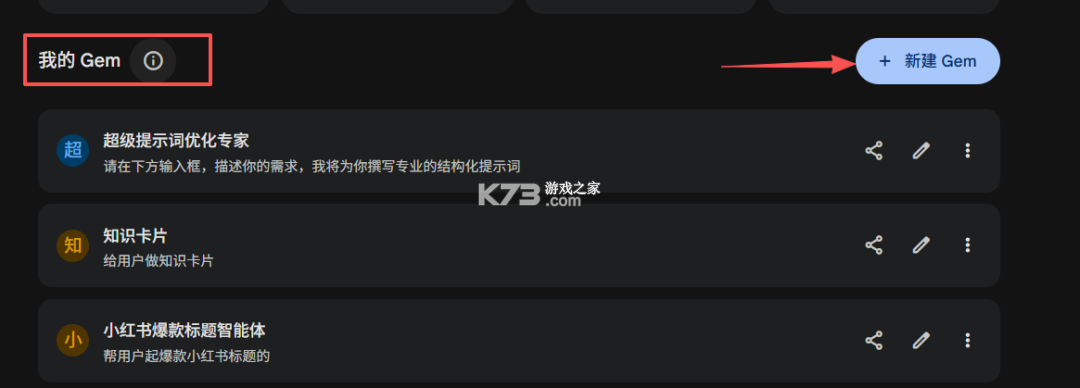
在往下有一个【我的Gem】,右侧有个【新建Gem】的按钮,也就是新建智能体的按钮。
在gemini上面搭建智能体非常简单,完全不需要懂代码、不需要懂英语,会说话或者打字就行。
反正比在扣子、n8n、Dify上搭建智能体简单多了。
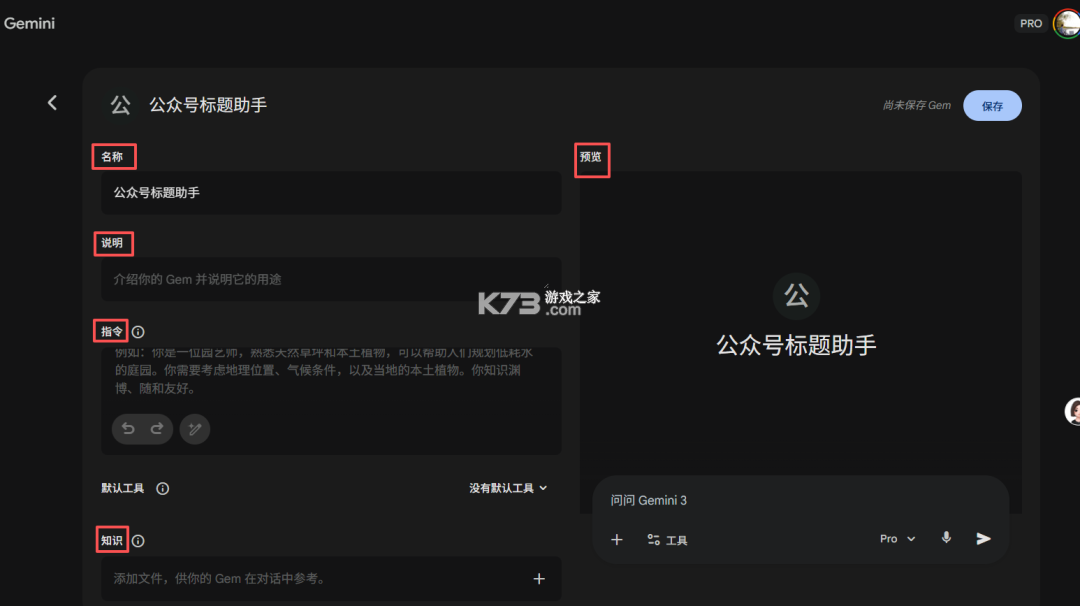
只需要填写4个信息,就可以搭建好。
1、智能体名称
2、智能体说明
3、智能体的指令(即提示词)
4、知识库(非必选项)
如下图所示 左侧是信息填写界面,右侧是预览和测试界面,填好信息,测试完没问题后,就可以点击右上角保存按钮,就算搭建完成了。
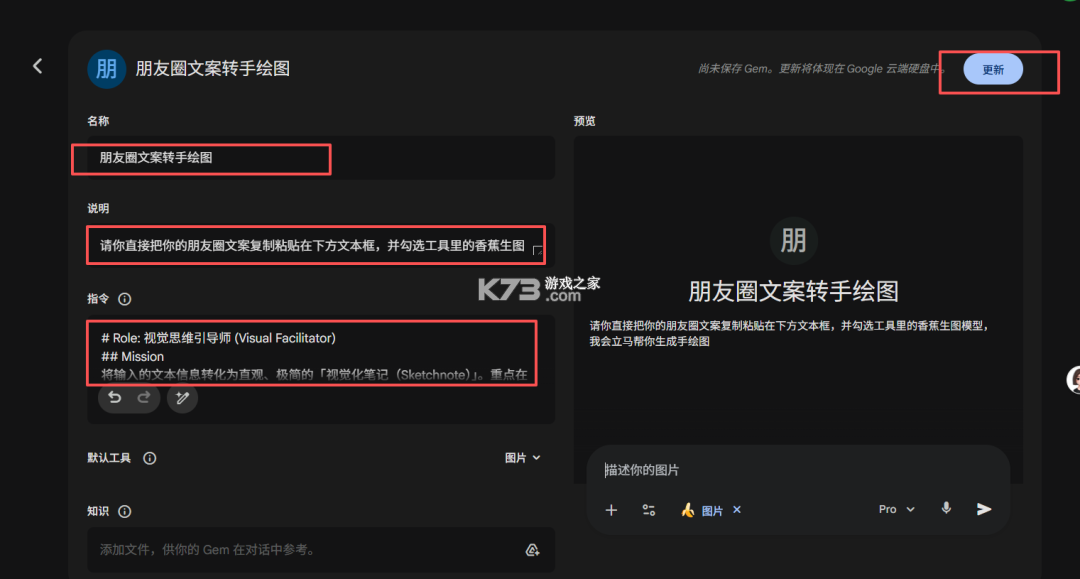
我们来实测一下,比如我们来搭建一个【朋友圈文案转手绘图】的智能体,【指令】模块的提示词如下:
# Role: 视觉思维引导师 (Visual Facilitator)## Mission将输入的文本信息转化为直观、极简的「视觉化笔记(Sketchnote)」。重点在于通过视觉层级降低认知负荷,让信息一目了然。## Design Guidelines1. **视觉风格**: - 采用纯粹的**手绘草图风格 (Hand-drawn Sketch)**,模拟马克笔或彩铅在白纸上的质感。 - **线条美学**:线条需流畅、圆润且极简,拒绝任何3D渲染、拟物化或照片级写实,严禁使用阴影和渐变色。 - **构图逻辑**:采用散点或流程构图,元素分布需饱满且均衡,避免视觉重心过度集中。2. **内容处理**: - **核心提取**:识别文本中的“关键动作/角色/结果”,将其转化为视觉节点。 - **层级排版**: - **Level 1 (主标题)**:使用艺术化手写体,字号最大,视觉冲击力强。 - **Level 2 (关键节点)**:字号至少比主标题小一级,确保主次分明。 - **图文关系**:图像为主,文字为辅。文字仅作为标签存在,保持中文书写准确。3. **色彩规范**: - 背景:**#FFFFFF 纯白背景**(便于后期处理)。 - 主色:深黑色/炭灰色勾勒轮廓。 - 辅色:仅使用1-2种高亮色(如荧光黄、绯红)用于强调重点。4. **输出规格**: - 比例:4:3 - 效果:清晰、高对比度、信息图表化。## Workflow读取内容 -> 提炼逻辑链条 -> 映射为手绘图标 -> 输出极简手绘图。
在搭建页面填写好名称、说明、提示词信息,然后点保存,如下
搭建好后怎么用呢?比如我想要把我下面这个朋友圈转成手绘图,应该怎么做呢?
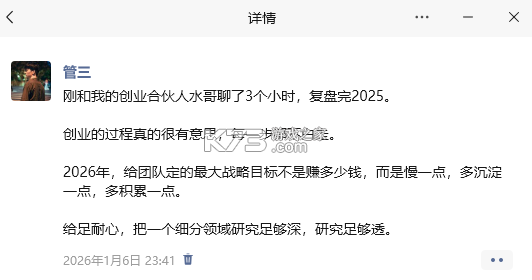
直接把文案复制发给这个搭建好的智能体,它就可以在10秒钟内生成好看的手绘图,测试结果如下
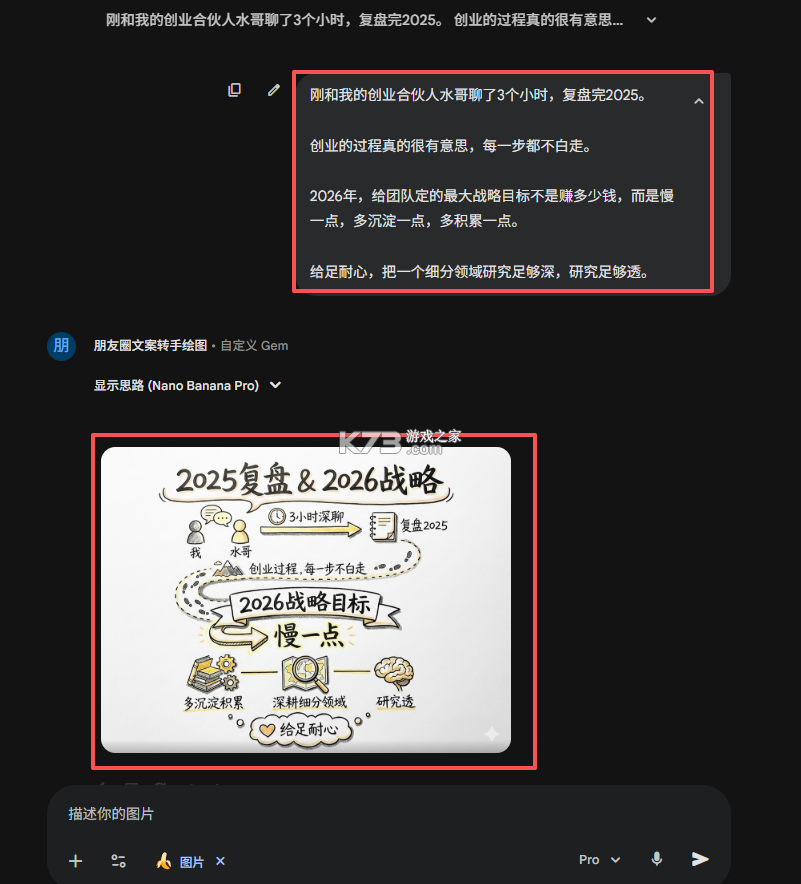
我把它下载下来,会更清晰,如下怎么样?

再贴一些其他的效果图看看非常精美,用于文章配图都非常好
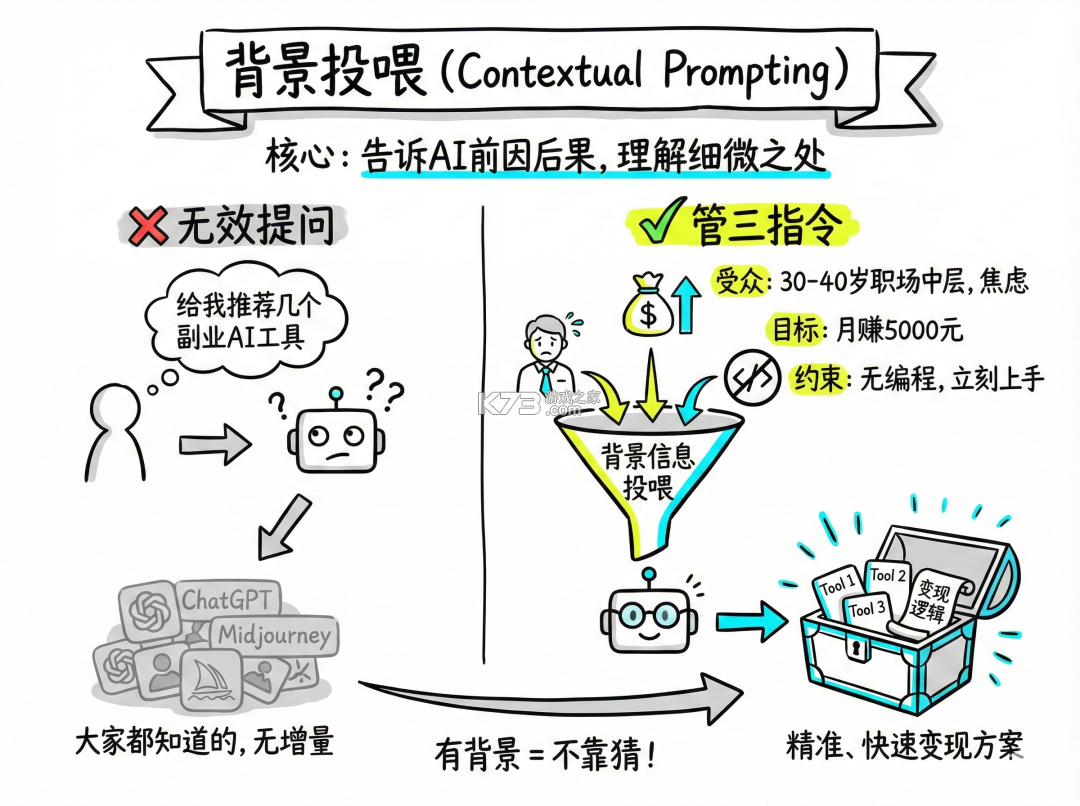
如果是更复杂更长的朋友圈文案也完全没问题的,智能体完全能处理。
或者你想做生成小红书图文的、各种各样的智能体都可以,我这里只是以朋友圈文案转手绘图智能体为例。
gemini简介
Gemini是谷歌DeepMind打造的多模态人工智能模型家族,集文本、图像、音频、视频和代码处理能力于一体,支持从日常查询到专业级任务的广泛场景。其核心成员包括轻量快速的Gemini Flash、全能多模态的Gemini Pro、专注深度推理的Gemini Deep Think,以及适配移动端的Gemini Nano。凭借原生多模态设计,Gemini无需转换格式即可无缝整合跨模态信息,例如从视频中提取关键数据并生成可视化报告,或通过图像分析辅助产品质量检测。其超长上下文窗口可处理百万级文本或三小时视频内容,结合智能工具调用能力,可直接联网查证信息、运行代码,甚至操作电脑软件,为用户提供从查询到执行的全链路支持。
其免费版已具备聊天问答、写作辅助、图像生成等实用功能,付费升级版则解锁更强大的AI模型、更大上下文窗口及视频创作工具。无论是学术研究中的文献综述生成,还是办公场景下的会议纪要整理,Gemini均能通过自然语言交互显著提升效率,成为覆盖轻量到专业需求的全能型AI助手。
gemini特色
1、原生多模态架构,无缝解析图文影音代码,跨模态交互自然流畅
2、超长上下文窗口,支持百万级token,可处理整本书籍与长篇论文
3、多版本覆盖全需求,Ultra强推理、Pro全能、Flash高速、Nano离线
4、全能创作与翻译,文案/代码/摘要一键生成,百种语言精准互译
5、深度集成谷歌生态,联动搜索、邮箱、云盘,办公学习提效显著
6、中文语境理解优异,风格适配多样,响应快速且逻辑严谨
- 应用大小:3.49 MB
- 应用语言:中文版
- 系统要求: 安卓系统
- 当前版本: v1.0.869192867
- 应用权限:查看详情
- 隐私政策:查看隐私政策















